关键词:语义化重组;知识服务;关联数据;语义网;知识组织
摘要:档案知识服务的智能化能力与档案数据的语义化程度紧密相连。本文基于档案知识组织现状和语义网与关联数据的思想,分析了面向知识服务进行语义化重组的必要性,提出档案语义化重组需要从数据形式、资源描述、关系表达和聚集效率四个方面满足机器的可读、可理解、可推理和自动化要求,进而构建由数据提供层、语义描述层和知识聚合层三个核心层次构成的语义化重组模型。档案机构在语义化重组的实施过程中,可以从需求分析、知识建模、知识加工和知识发布四个环节展开,并通过测试与迭代,改进数据重组质量。
本期,我们将向大家推出研究员成果“数据管理专题”系列的第三篇——夏天、钱毅《面向知识服务的档案数据语义化重组》
戳此链接快速回顾本系列往期推文:


面向知识服务的档案数据语义化重组
中图分类号:G270.7
引文格式:夏天,钱毅.面向知识服务的档案数据语义化重组[J].档案学研究,2021(2):36-44.
引 言
1 研究背景
在国内,段荣婷建议基于SKOS语言对《中国档案主题词表》进行语义表示[12],并对档案著录信息进行本体化转换[13],是将档案数据转换为符合语义网规范数据的尝试。此外,基于关联数据进行资源聚合可以增强档案知识服务的能力,在该方面,吕元智呼吁以关联数据为工具,研究数字档案资源的知识组织,初步构建了数字档案资源知识关联组织的框架模型[14],后续又针对不同媒体类型的数字档案资源聚合问题,提出了数字档案资源跨媒体聚合框架[15]。郭学敏和Ryan Shaw则基于文献分析法,探讨了如何将档案数据转换为关联数据,与多数研究观点一致,认为本体是实现档案资源真正关联、共享与重用的关键[16]。
整体而言,人们对于档案知识服务的重要性已经有了充分认识,语义网与LOD在档案利用中的作用也引起了人们的重视,并初步开展了关于档案主题词表、著录项等数据的语义表示和关联组织探索。理论上,档案知识服务的价值源泉来自底层的高质量档案数据,由于语义网与LOD目标宏大,技术体系复杂,如何借鉴其在知识组织,尤其是具体的实体关系关联组织方面的思想,对档案数据进行语义化重组,仍需要进一步深入研究。
2 档案数据语义化重组的必要性
随着用户信息素养的提高,人们对档案服务的期望也在不断变化,迫切需要在档案展览这类被动式输出和“关键词输入、列表式呈现”的常规检索服务之外,提供层次更深、范围更广的知识服务,如蕴含在人事、合同、产品等来自不同业务部门档案之间的网络关系发现,人物档案相关的人、事、物关系分析与背景描述。这类服务能否实现的关键,在于底层有无含义和关系都定义明确的高质量机读数据。
从整体趋势来看,电子档案数据的机器可读能力在不断提升,但其媒介类型日趋多样,文本、图像、音频、视频等多种形式并存。在数据质量方面,虽然档案数据的结构化程度已有显著改善,但相对于知识服务的数据要求依然有较大差距,当前广泛采用的档案元数据和分类与主题组织方式,尚无法完整支撑知识服务对数据理解的要求。
2.2 档案元数据在支撑知识服务时存在局限
传统的档案知识组织系统包括元数据、规范档、分类法、叙词表等。其中,分类法、叙词表虽然具有一定的层次结构和等级关系,但关系表达简单,结构单一,不能解决语义异构问题。元数据是目前描述档案内容、背景和结构信息以及过程管理信息的主流方法,档案管理机构通过遵从有关元数据规范,实现对档案数据的描述和控制。在管理层面上,元数据分布总体是面向业务处理与性能考虑的,其关联关系通过系统内部程序进行维系,数据与关联的独立性受到系统本身制约,因而一旦档案对象脱离系统进行长期保存或提供给第三方使用时,往往需要再将实体与元数据进行合并封装,档案的关联关系难以得到保障。
虽然元数据在档案管理过程中具有不可替代的重要作用,但直接以元数据作为知识服务的数据组织方式,存在明显不足。
(1)别名问题
现实世界中,经常存在同一事物拥有多种不同名称的别名现象,如中医药档案中的硼砂与月石,人物档案中的鲁迅与周树人,历史档案中的前汉与西汉。在元数据应用实践中,人们难以做到对实体别名的穷举式著录,别名与目标对象之间缺少显式的链接关系,实体名称的变更将会导致档案链之间的断裂,因此,当用户在系统中以别名进行档案查询时,不能保证返回结果的查全率。
(2)歧义问题
元数据方案虽然对档案的构成要素作出了详细规定,但元数据值的数据类型多为简单字符型,在描述事物时难以避免歧义现象。例如,口述历史电子档案元数据方案中的口述者元数据、DA/T 54—2014照片类电子档案元数据方案中的人物元数据,均以人物姓名的字符串进行捕获或著录,由于现实生活中存在大量同名现象,单纯采用字符串不易区分同名人物的差异,以常见姓名“李克”为例,在百度百科词条下,具有一定网络知名度的“李克”就达29位,既有篮球运动员,又有导演,名同人异。元数据应用中的这种歧义问题,如不加以处理而直接输入知识服务系统,则查准率较差。
(3)关联推理问题
知识服务不仅需要实现对档案描述信息和档案全文的传统匹配式检索,还需要支持关系推理,能够从已有信息中得到更多隐含的知识,例如,从档案中发现人物之间因专业技能、工作经历、社会关系等形成的隐含链接关系及其关系强度。
然而,档案元数据的现有组织方式并不适合关系推理。元数据项的作用及各项之间的逻辑关系,通常是由文字形式的规范文档进行描述并由人解读,缺少机器可推理的显性表达形式。直接以全文检索或关系数据库方式存储元数据值,只能实现字段级别的组合查找,无法根据档案数据中的关联关系,实现语义关系推理,例如,干部档案与人事档案之间的上下位关系。显然,元数据组织方式与智能化的档案知识服务要求,尚有一定差距。
(4)知识复用问题
在档案管理系统中,元数据在底层多采用关系数据库存储,缺少通用的数据表示和交换格式,当将元数据复用于新的知识服务功能时,数据转换成本较高。此外,不同元数据标准对相同对象的描述并不统一,同样是档案门类代码,在《录音录像类电子档案元数据方案》(DA/ T 63—2017)中,采用“M3”进行编码,而在《口述历史电子档案元数据方案》(DA/T 54—2015)中,则采用“M2”编码,在面对机器自动处理时,缺少显性的互指关联关系,这种概念表述上的不统一,不利于将各类专题数据直接汇聚形成更大规模的知识库。元数据在知识复用方面的不足,不利于档案信息资产的保值增值。
综上可见,元数据本身并不是直接面向上层知识服务设计形成,其信息组织方式虽然解决了机器可读和基本的规范描述问题,但尚未解决实体本身的别名、歧义以及机器自动推理难题,无法达到知识服务对数据的操纵粒度和语义要求。
2.3 语义化重组是开展知识服务的必由之路
智能化的知识服务要求有更细的知识粒度和更好的组织形式,消除描述对象的表达歧义,支撑档案馆内部甚至是跨部门跨机构之间的知识共享,打破档案资源与其他信息资源的界限。现有的电子档案以及通过档案著录、元数据捕获等手段形成的数据,并不能直接满足智能化知识服务的计算语义要求。为解决知识表示、共享、复用和推理问题,万维网之父Tim Berners-Lee于1998年和2006年分别提出了语义网和关联数据的思想,经过多年的发展,语义网相关标准和技术逐步成熟,不仅成功指引了Web3.0数据网的发展方向,更为新一代知识服务提供了知识加工的理想方式和可行的技术路线。
知识重组是开展知识服务的前提,今天,知识重组的目标与传统知识组织已有显著不同,传统的分类和叙词表主要是为人使用,便于档案的分类管理和检索,而语义网时代的知识组织则是在传统知识组织的基础上,让机器也能够读取、处理并理解数据中蕴含的语义,使机器能够在语义层级上进行数据的处理分析。实体构成世界,而非字符串,档案知识服务应从机器角度出发,探索档案数据的语义化知识重组方法,让档案知识组织从基本的机器可读向可理解、可推理、可计算的目标迈进,完成档案数据从“字符串”描述为主向“实体”语义描述的转变,为实现跨媒体的文本、音频和视频知识集成服务[18]奠定基础。
3 档案数据语义化重组的要求
智能化的档案知识服务要求档案数据高度形式化,采用标准通用的数据表示语言承载知识,去除对特定软硬件环境的强依赖,保证数据具备机器可读和可交换的形式化特点,进而达到知识长期可复用的目标。
在现实应用中,档案数据多以关系数据库进行组织管理,数据高度依赖于具体的数据库管理系统和档案信息系统。当面向知识服务时,基于可读、可交换和可长期复用的形式化需求,还应转换为更为开放的格式,如符合W3C语义网规范的RDF、Turtle、JSON-LD等格式,开放的标准化编码格式具有跨平台跨领域的优势,能够被大部分编程语言和新型的适合知识推理的图数据库支持,从而脱离特定系统的强依赖,使知识变成真正易于“机器可读”的数据,为自动化知识处理奠定形式基础。
3.2 资源描述要求——机器可理解
让机器理解人类信息一直是科学发展的永恒主题,为此,W3C提出了RDF资源描述框架,用主体(Subject)、谓词(Predict)、客体(Object)构成的三元组模型,简称SPO,作为描述资源的元数据和知识表示的基本框架,实现让机器理解机器的有限目标,部分学者把这些相对独立又能够关联在一起的三元组称为档案知识元[14]。
在RDF三元组模型中,主体是谓词描述的对象,其属性特征可以通过定义从同类对象中抽象出来的概念来界定;谓词是严格定义的术语,是描述概念特征的属性,表示主体和客体之间的关联关系;客体作为谓词的取值,不仅可以是数据,还可以是另一个对象。在该模型中,知识的基本粒度被细化为三元组形式,即每一个三元组代表一条知识,每一个资源则由若干三元组予以描述,三元组模型以简洁、普适和规范的形式,超越了系统、平台和领域的限制,使得机器与机器之间的相互理解成为可能。
档案资源描述的理想目标是通过对档案资源进行细粒度、无歧义的三元组形式的规范化描述,将档案知识由档案整体描述深入档案内部的内容表示方面,满足机器可计算和可理解的语义要求。
目前,主流档案信息系统中的元数据记录所描述的对象是实体档案或电子文件,基本以文件级档案为最小著录单位,主要描述档案的基本特征,方便档案管理和利用人员定位和查阅。为实现档案数据的机器可理解,有必要采用细粒度的三元组方式对档案资源进行转换重组,方便机器的无歧义计算,从而有利于机器根据知识单元的各项特征属性进行统计和挖掘分析。
在采用三元组资源描述方式时,需要确定档案领域概念及其属性的定义,包括名称选择、值域类型与范围限制、唯一标识、概念映射等,这种某一领域内可共享的概念及其概念间关系的形式化定义被称为知识本体,本体是未来档案资源描述的主要方法和技术之一。档案知识表示的语义化首先需要有可共享的概念及概念间关系的形式化定义,这些定义通过档案本体予以规范,因此,构建档案本体是档案资源描述的重要基础工作。
简而言之,考虑到现阶段语义描述技术的发展现状,以RDF三元组形式对档案资源进行描述,重组为细粒度的档案知识元,具有必要性和可行性。
3.3关系表达要求—机器可推理
无论是形式上保证数据的机器可读,还是描述上保证资源的机器可理解,最终目的都是为了支持知识的自动推理。将档案资源组织成三元组描述格式的档案知识元,仅是保证机器可推理的必要条件之一,机器可推理还需要在此基础上,进一步对资源之间的关系表达进行建模。
档案资源存在两类典型关系:一是特定档案资源集合内部存在的关系,如依托业务职能形成的业务链关系,依托业务流程形成的往复与顺序关系等,对这类关系可直接采用属性与属性值的形式转换为RDF三元组,虽然满足资源描述的规范化要求,但不利于通用程序的推理分析,因此需要通过关系建模明确表达概念之间存在的关系。二是档案资源与整体档案知识体系的关系,比较典型的如对在档案资源进行主题、分类等描述时所依赖的知识体系中蕴含的关系,为此,需要将《中国档案主题词表》中存在的等同关系、属分关系以及相关关系通过语义化重组来满足机器推理需求。
机器可推理要求采用具备推理能力的关系建模语言,实现档案资源关系表达的显性化。典型的关系建模语言有RDFS(RDF Schma)、OWL(Web Ontology Language)和SKOS(Simple Knowledge Organization System)。其中,RDFS是W3C早期提出的建模语言,所支持的关系表达能力有限,仅支持资源(包括属性,属性是一种简单的资源)的上下位关系和定义域、值域的限定,如通过rdfs:Class、rdfs:Resourc和rdfs:subClassOf表达类以及类之间的层次关系。RDFS的特点与关系表达悖论有关,即关系的表达能力越强,机器实现的难度和代价就越大,RDFS优先考虑推理程序的可实现性,符合当时的硬件状况和语义网以“有限目标”迭代演进的技术路线。
在RDFS之后,为提供快速灵活的建模和高效的自动推理能力,W3C于2004年推出了OWL(Web Ontolog y Language),并于2009年将OWL升级为OWL2,OWL2已经成为目前语义网和知识图谱领域之中最为流行的本体建模语言,具备丰富的关系表达能力。
此外,考虑到已有知识组织系统的互操作要求,实现传统主题词表、分类法的机器可存取、链接和复用,W3C又发布了简单知识组织系统SKOS,提供符合语义网要求的规范化语法来声明不同概念体系中概念间的映射链接,例如:skos:exactMatch对应等同映射;skos:broadMatch和skos:narrowMatch对应两概念间的层次等级映射;skos: relatedMatch对应两概念间的相关映射;skos:closeMatch对应非精确等同,表示两个概念的部分相似。为充分表达两个概念的重合程度,还定义了majorMatch、minorMatch属性,分别表示重合较大及重合范围较小两种情况,并允许概念类之间进行集合的交并补运算,以表达复合等同的情况。SKOS定义了经由网络而共享与链接各种知识组织系统的共同数据模型,提供了将现有知识组织系统,如《中国档案主题词表》,迁移至语义网的标准、低成本的路径[12]。
知识聚集要求采用必要的技术手段,提高知识聚集的效率,尽可能让机器能够自动转换、抽取和链接各类知识,编织形成一张由多种来源的档案知识元相互关联而成的知识网络。
其中,转换是自动聚集知识的最常见手段,适用于将结构化数据转换为语义化数据的场景。例如,对于档案信息系统中已经高度结构化的档案描述信息,可以直接由关系数据库中的记录形式转换为RDF三元组形式。在已有结构化数据的转换方面,W3C RDB2RDF工作小组制定了两种标准方法:①直接映射DM(Direct Mapping),该方法直接将关系数据库中的数据表作为本体中的类,列作为属性,行作为实例,字段值作为属性值,映射为RDF格式;②关系数据库到RDF映射语言R2RML(RDB to RDF Mapping Language),R2RML提供了一组标准的转换语法,允许用户灵活设置映射规则,解决DM方法难以向自定义本体快速映射的不足。此外,将传统的档案分类、主题等组织方式通过SKOS等互操作语言转换为语义网形式,也属于档案知识聚集的转换手段。
抽取主要针对档案内容中的非结构化或者半结构化数据的语义化组织场景。例如,从文件的原始文本、音频或视频中抽取出相关的人物、机构、事件及其描述信息,并转化为RDF三元组。目前,这一类知识片段的抽取多通过编写特殊规则或者人工补录完成,构建成本依旧较高且实时性不强。随着人工智能技术的发展,尤其是信息检索与自然语言处理领域中的关键词与关键短语提取、命名实体识别、关系抽取、图片与音视频的自动文字描述、自动标引等技术的成熟,借助机器智能实现档案知识元的发现和抽取,将会成为知识聚集自动化的重要手段。
链接则用于将档案知识元与其他世界知识建立关联,增强档案知识服务的推理能力。例如,DA/T 46—2009可借助于其核心术语“XML”与DBpedia进行链接,丰富档案的背景知识和检索利用能力。W3C在语义网实施过程中,采取了分而治之的策略,鼓励各领域、各机构以开放关联数据方式发布所拥有的知识,并通过知识链接实现人类知识全世界无歧义共享的宏伟目标。近年来,开放关联数据在全世界迅速增长,国内也已有部分成功实践,如上海图书馆推出的家谱关联数据[20]和SinaPedia中文百科语义资源[21],中国中医科学院构建的中医药知识图谱[22],基于百度百科和互动百科构建的zhishi.me[23]等。
4 档案数据语义化重组模型
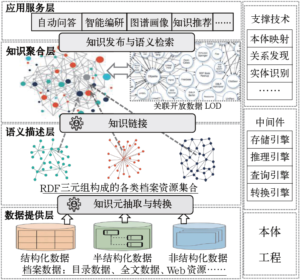
图1 档案数据语义化重组模型
在模型中,数据提供层是语义化重组的基础,凡是需要检索利用的档案数据均可以作为语义化重组的素材,如目录数据、全文数据、音视频数据、Web档案资源等。根据结构化程度的不同,档案资源可分为结构化、半结构化和非结构化三类,这些不同类型的档案数据所采用的重组方法不尽相同。以关系数据库为典型代表的结构化数据,可以直接通过R2RML等工具转换为RDF三元组;以Excel、XML、JSON等格式存储的半结构化数据,可以通过编写特殊规则进行转换;而大量保存在档案文本中的知识,则需要通过自然语言处理技术进行抽取,获取有价值的档案知识元。随着深度学习对感知类数据处理能力的极大提升,音视频类档案可先自动转换为文本描述,进而提取其知识元并链接到档案知识网络。
语义描述层对数据提供层的各类档案数据进行语义抽取和转换,利用RDF三元组解决数据语义的形式化和明确化描述问题,形成若干不同种类的档案语义数据集。
由于档案类型多样,直接构建复杂完备的档案知识体系在实践中可操作性不强,“分治”是解决复杂问题的经典方法,无论是语义网在世界范围内的演进,还是大数据在分析架构方面的设计,都采用了“分治”思想。因此,语义描述层不强求对各类档案资源的统一处理,推荐采用分治策略,在采用规范的语义描述手段基础上,逐步实现各类档案数据的语义建模和描述,例如,借助于SKOS,将《中国档案主题词表》《中国档案分类表》中的等同关系、等级关系、相关关系等显性的档案知识语义化;将人事档案中的人物概念图谱化;将文书档案中的机构、事件、人物、主题等隐性关系显性化。语义描述层的结果将为机器可处理的档案语义知识空间构建奠定语义资源基础。
知识聚合层关注各类档案资源之间的语义关联问题,这些语义资源既包括档案语义描述层形成的档案领域内部资源,也包括与档案相关的外部关联开放数据,进而通过语义互操作[10]、本体映射与融合等技术,实现不同语义数据集的知识聚合,从而构成一张巨大的档案知识网络。这张网络不仅可以打通档案机构内部的信息互联,增强对档案背景知识的理解,还可以实现与图书馆、博物馆等文化服务机构的资源互通,提升档案被发现和利用的能力。
知识聚合多采用本体映射和语义互操作技术,例如,将档案著录数据与Schema.org, FOAF, LODE, GeoNames等值词汇表进行映射建立链接[26],利用中介词典将档案概念实体与DBpedia、Freebase中的对等实体关联在一起,通过词语相似度计算将名称规范档数据与Wikidata进行聚合[27]。在聚合过程中,欧洲数字文化资源整合项目Europeana的关联数据模型EDM(Europeana Data Model)、国际博物馆理事会CIDOC提出的面向对象的参考概念模型CIDOC—CRM、SKOS等知识组织方法,都可以起到中介词典的角色[16],实现多源异构数据中异质实体的语义链接。
此外,知识聚合层还需要提供必要的知识发布和检索手段,知识发布将聚合的档案知识以关联数据方式进行发布,方便档案数据在网络上以标准化方式被发现和获取,语义检索则支持用户或软件模块以SPARQL等标准化语言进行检索,方便知识的检索利用。
语义化重组的配套设施主要有三大类:知识表示的本体工程、语义提取的关键技术、知识存储利用的中间件。其中,本体工程是语义化组织的重要环节,用于确定档案知识体系的概念模型,档案数据需要在概念模型约束下,形成无歧义、可推理的三元组档案知识元。支撑技术则指知识重组所依赖的关键技术,包括将不同知识体系进行链接的本体映射技术,提取自由文本中知识元的实体识别和关系发现技术,图像视频的自动文本描述技术等。
中间件为知识处理过程中用到的基础性软件,存储引擎用于知识的存储,如图数据库Neo4J,RDF三元组数据库Jena TDB、OntoText GraphDB;推理引擎用于支持在语义知识库中进行各类复杂推理,如Apache JENA;查询引擎提供常规的知识检索处理,如支持SPARQL语法的Apache ARQ,面向NEO4J属性图查询的Cypher;转换引擎则用于常见结构的数据向语义存储结构的快速转换和语义发布,如R2RML工具R2RML Parser[28]、D2RQ,支持非关系数据库向RDF转换的xR2RML[29]。
5 档案数据语义化重组的实施路径
语义化重组的主要步骤可以分为需求分析、知识建模、知识加工和发布应用,各步骤之间虽然具有一定的顺序依赖关系,但由于需求、场景、人们对数据语义表达的认识、软硬件技术条件的变化,知识重组会存在多次反复的情况,需要在测试和迭代中不断提升档案机构的知识组织和服务能力。
需求分析的目的是使档案机构了解档案服务的发展方向、未来知识服务对底层数据的粒度和形式要求,明确当前亟须解决的阶段性任务,并调研现有档案数据的形态、关系和稳定性,确定语义化重组的数据范围和基本方法,以有限目标分阶段推进档案知识服务能力的建设。
对于整个档案行业来说,主管机构可以借鉴其他领域的成功经验,如参考国际图联(IFLA)的做法,成立数字档案资源知识关联组织联盟,由联盟共同制定行业通用的相关标准、数据模型等。对于单个机构来说,则可成立专门的需求分析小组,基于知识服务的最终目标对原始档案数据进行剖析,了解已有数据的内容结构、潜在的外部关联数据,为知识建模做准备。在实践中,单个机构和整个行业的知识组织目标的侧重点有所不同,从行业或者整个人类社会知识利用需求的角度来说,档案数据的标准化开放互联至关重要,人们期望每个具体的档案机构均能以关联数据格式发布共享,在需求上更强调档案知识的完整、稳定、有效,知识组织应满足关联数据的基本原则,实现档案知识跨机构共享。对单一机构来说,则更加关注将哪些数据以何种方式进行语义化再组织,支撑上层的智能化知识服务。
知识建模通常指本体设计,用于确定档案数据中的抽象概念、概念的属性及其之间的各种关系,如等级关系、等同关系、相关关系、逻辑关系、引用关系等,并通过数据的提炼分析形成共同理解和认可的词汇集,用明确规范的术语进行概念表达,让档案数据重组有统一规范的模式可以参考。
本体设计的常用方法有TOVE法、IDEF-5法、METHONTOLOGY法、七步法等,其中,由Natalya F.Noy与Deborah L. McGuinness提出的七步法[30]在领域本体构建中较具代表性,步骤包括:①确定本体的领域和范畴;②考虑现有本体的复用;③列出领域中的概念术语;④定义类和类的等级体系;⑤定义类的属性;⑥定义属性的分面;⑦创建实例。文献[31]在此基础上,增加了第八个步骤“检查异常”,通过异常检查结果反馈到前期的本体设计。知识建模各个工作环节并非严格的线性递进,通常会反复多次,不断完善以保证所设计知识体系的可用性。
知识建模的结果应包括核心元素集、元素间的交互作用以及这些元素到规范语义间的映射关系,如何确定概念和关系的名称以及对象的标识是知识建模的重要内容。为保证知识的交流、共享、互操作和可重用能力,概念名称应尽量复用使用广泛的词汇,如DCMI(Dublin Core Metadata Element Set)、FOAF(Friend of a Friend Vocabulary),文献[32]收集了多达60个常用的词汇集,可供档案机构在知识建模中参考选用。自定义名称则可借鉴《中国档案主题词表》《中国档案分类表》中的词汇,保证概念易于理解和认可。对象标识则可以遵从关联数据的设计原则,即采用URI标识对象,以保证对象的全局唯一性。
知识加工基于知识建模得到的抽象概念模型,对档案数据进行转换、抽取和链接,实例化具体的档案实体对象及其属性关系,形成三元组形式的档案知识元集合,并构成档案知识图谱。本质上,概念模型代表了团体的共识,用于知识的组织管理,而知识图谱强调实体个体的描述与利用。如果把知识图谱看成由模式图和数据图两层内容构成的知识网络,则模式图与知识建模紧密相关,数据图则对应了知识加工得到的语义化数据对象。
转换和抽取对应了两类不同类型数据的语义化组织方法,转换工作意味着原始数据已经高度结构化,与目标转换对象有较为明显的逻辑映射关系,其处理方法有一定的通用性。例如,存在于档案信息系统的内部数据库且有明确数据字典定义的数据,可以通过前述的R2R工具转换为RDF三元组;叙词转换则可以把档案叙词表资源利用SKOS转换为三元组形式。对于档案文本、音频、视频等非结构化数据,则需要利用各种智能抽取技术,获取内容中蕴含的档案知识,如命名实体识别、关系发现、实体链接、知识融合等相关技术。此外,Excel、CSV等半结构化形式的档案数据,同样可以应用转换或抽取技术,将蕴含的知识元纳入知识网络之中。
知识链接工作把外部可用的知识源与内部档案知识进行关联,通过关联开放数据增强档案知识图谱的规模,实现多源知识的语义融合,例如,将档案中的人物实体与开放百科知识进行链接,补充人物的背景描述信息。语义匹配是实现知识链接的关键,常用策略包括基于资源URI引用或等价标记的语义集成[33]、通过中介词汇表的语义映射等,例如,在LOD云图中,最常使用的3个链接谓词分别为owl:sameAs、rdfs:seeAlso、skos:exactMatch,利用这类谓词可以将实体与已有开放数据快速链接。
发布利用阶段需要提供URI基础设施和语义检索接口,将语义化重组得到的数据,以规范方式实现跨部门、跨机构的高效共享和复用。
基于关联数据原则,任意一个档案实体都应赋予一个可全局定位的唯一URI标识。发布利用阶段将同时提供必要的URI基础设施,通过该设施实现对资源URI的定位和共享。典型的URI基础设施具备内容协商机制,能够根据用户请求差异,自动返回RDF、JSON-LD、HTML等不同类型的数据格式,同时满足机器处理和人的阅读需求。除了用于实体定位和访问的URI基础设施外,档案机构还需要提供必要的语义检索接口,供上层的知识服务调用,例如,嵌入SPARQL端口服务作为数据消费接口,接收复杂的SPARQL查询语言,返回匹配的实体关系。
发布利用不仅可以用于机构内部的知识服务,还可以提供数据消费接口和权利声明,将可以公开的语义化档案数据发布到LOD云中,促进关联开放数据的发展,让全世界可共享的巨大人类知识网络之中亦有档案人贡献的知识节点。
6 结 语
求木之长者,必固其根本。档案知识服务向智能化发展的过程中,尤其需要重视对档案数据的语义化组织,保证重组后的数据在智能社会中,对于机器具备形式可读、描述可理解、关系可推理,可以与其他语义数据集高效率链接聚合等特性这种语义化重组将通过对已有档案数据的转换抽取和知识链接实现,实施过程中会涉及需求分析、知识建模、知识加工和发布利用等多个环节。
面向知识服务的语义化重组,虽然吸收了开放关联数据的知识组织方法和技术,但与开放关联数据的目标不尽相同。开放关联数据强调事物的发现、聚合和共享,即通过数据发布被发现,通过链接聚合实现跨机构共享,强调对他人的便捷利用。而档案机构本身的语义化工作,重在满足本机构的知识服务需求,更关心数据在内部如何组织加工,实现手段相对灵活。因此,并不是所有的档案资源都需要发布为关联数据,但是所有的档案资源都应该可以被语义化重组,在安全受控范围内支撑档案知识服务。
原文载《档案学研究》 2021 年第 2 期,经杂志社授权后发布。
扬州大学-邵亚伟:
随着档案事业的发展,档案信息资源结构不断优化,档案机构的服务能力持续提升、服务形式屡屡创新,档案用户的需求也愈加个性化、多元化……传统的档案信息服务向更加创新、主动、智能的档案知识服务转型是提升档案信息资源利用效率、促进档案事业发展的重要路径。当前,档案知识服务所需的软硬件技术已相对成熟,但档案数据作为档案知识服务的价值源泉,却因媒介类型多样、数据治理参差不齐等问题难以支撑档案知识服务全程、保障档案知识服务质量。在这一背景下,本文一方面引入了语义网和关联开放数据(Linked Open Data,LOD)的相关标准与技术,为档案机构组织档案资源、提升知识服务能力提供新技术与新思路;另一方面,本文认为档案数据语义化重组是将已有档案数据有效运用于档案知识服务的必要过程,故分析了档案数据语义化重组的必要性和要求,并建构了包含数据提供、语义描述和知识聚合三个层次的档案数据语义化重组模型,为档案机构开展需求分析、知识建模、知识加工和知识发布等工作的档案数据语义化重组提供了实施路径参考。总的来说,面向知识服务的档案数据语义化重组虽然吸收了开放关联数据的知识组织方法和技术,但仍保持着档案工作的自身特色,对于推动档案工作的转型和档案事业的发展具有重要意义。
[1] 张璐,申静.知识服务模式研究的现状、热点与前沿[J].图书情报工作,2018(10):116-125.
[2] 张斌,郝琦,魏扣.基于档案知识库的档案知识服务研究[J].档案学通讯,2016(3):51-58.
[3] 牛力,王为久,韩小汀.“档案强国”背景下的档案知识服务“云决策平台”构建研究[J].档案学研究,2015:74-77.
[4] 毕建新,郑建明.用户目标驱动的档案知识服务模型研究[J].浙江档案,2014(8):16-19.
[5] 徐拥军,周艳华,李刚.基于知识服务的档案管理模式的理论探索[J].档案学通讯,2011(2):24-28.
[6] 魏扣,李子林,金畅.社交媒体环境下档案知识聚合服务实现架构研究[J].档案学通讯,2018(6):61-66.
[7] 张倩.档案信息智能检索技术的创新应用研究[J].北京档案,2018(12):23-25.
[8] 胡小林.档案知识服务及其系统构建[J].档案天地,2003(3):27-29.
[9] 王应解.档案知识组织初探[J].档案学通讯,2008(2):25-29.
[10] 贾君枝.基于ISO 25964的词表互操作实现探析[J].数字图书馆论坛,2016(12):9-14.
[11] T. Heath, C. Bizer. Linked Data:Evolving the Web Into a Global Data Space[J].Synthesis lectures on the semantic web: theory and technology,2011(1):1-136.
[12] 段荣婷.《中国档案主题词表》语义网络化应用研究[J].档案学研究,2010(6):68-72.
[13] 段荣婷,马寅源,李真. 档案著录本体标准化构建研究[J].档案学研究,2018(2):63-71.
[14] 吕元智.数字档案资源知识“关联”组织研究[J].档案学研究,2012(6):46-50.
[15] 吕元智.数字档案资源跨媒体语义关联聚合实现策略研究[J].档案学研究,2015(5):62-67.
[16] 郭学敏, R. Shaw.基于关联数据的档案语义转换实践分析[J].档案学通讯,2019(5):50-57.
[17] 陈雪燕,于英香.从档案管理走向档案数据管理:大数据时代下的档案管理范式转型[J].山西档案,2019(5):24-32.
[18] 梁孟华.面向用户的数字档案资源跨媒体知识集成服务研究[J].档案学研究,2016(6):51-56.
[19] 钱毅.技术变迁环境下档案对象管理空间演化初探[J].档案学通讯,2018(2):10-14.
[20] 夏翠娟,刘炜,陈涛,张磊.家谱关联数据服务平台的开发实践[J].中国图书馆学报,2006(3):29-40.
[21] 陈涛,刘炜,朱庆华.中文百科概念术语服务平台SinoPedia的构建研究[J].中国图书馆学报,2018(4):4-18.
[22] 于彤,刘静,贾李蓉,等.大型中医药知识图谱构建研究[J].中国数字医学,2015 (3):80-82.
[23] N. Xing, S. Xinruo, W. Haofen, et al. Zhishi.me – Weaving Chinese Linking Open Data.[C]//The 10 th International Semantic Web Conference,2011:205-220.
[24] 翟姗姗,许鑫,夏立新,等.语义出版技术在非遗数字资源共享中的应用研究[J].图书情报工作,2017(2):23-31.
[25] 吕元智.基于用户利用行为分析的档案知识集成服务实现策略研究[J].档案学通讯,2018(5):56-61.
[26] K. F. Gracy. Archival Description and Linked Data: A Preliminary Study of Opportunities and ImplementationChallenges[J].Archival Science,2015(3):239-294.
[27] 贾君枝,赵宇飞.Wikidata与名称规范档数据聚合实现[J].情报科学,2018(11):74-79.
[28] N. Konstantinou, D.-E. Spanos, N. Houssos, et al. Exposing Scholarly Information as Linked Open Data:Rdfizing Dspace Contents[J].The Electronic Library,2014(6):834-851.
[29] F. Michel, L. Djimenou, C. Faronzucker, et al. Translation of Relational and Non-relational Databases Into Rdf with Xr2rml[C]// International Conference on Web Information Systems and Technologies,2015:443-454.
[30] N. F. Noy, D. L. McGuinness. Ontology Development 101:A Guide to Creating Your First Ontology(technical report) [M]. Stanford Knowledge Systems Laboratory, 2001:1-25.
[31] G. Antoniou, P. Groth, F. van Harmelen, et al. A Semantic Web Primer(3 rd Edition)[M].The MIT Press, 2012:193-213.
[32] D. Chandek-Stark, A. Coburn, M. J. Giarlo, et al. Rdfvocab: Common Owl/rdfs Vocabularies for Use with Ruby [EB/OL].[2020-02-16].https://github.com/rubyrdf/ rdf-vocab.
[33] M. Hausenblas. Exploiting Linked Data to Build Web Applications[J].IEEE Internet Computing.2009(4):68-73.